Thanks to perfect blue for these nice challenges! The Binary Tree and Switching it up reversing challenges were probably also doable but I didn’t really have the required skill to complete them within the given CTF duration 👍
🎵 Sander van Doorn x Lucas Steve - The World is actually so good.
| Details | Links |
|---|---|
| CTFtime.org Event Page | https://ctftime.org/event/1371 |
Misc
BTLE
I stored my flag inside a remote database, but when I tried to read it back it had been redacted! Can you recover what I wrote?
Author: UnblvR
Attached: btle.pcap
Opening up the capture file in Wireshark, we notice that a large percentage of the packets are just Empty PDUs from the Bluetooth Low Energy Link Layer (LE LL).
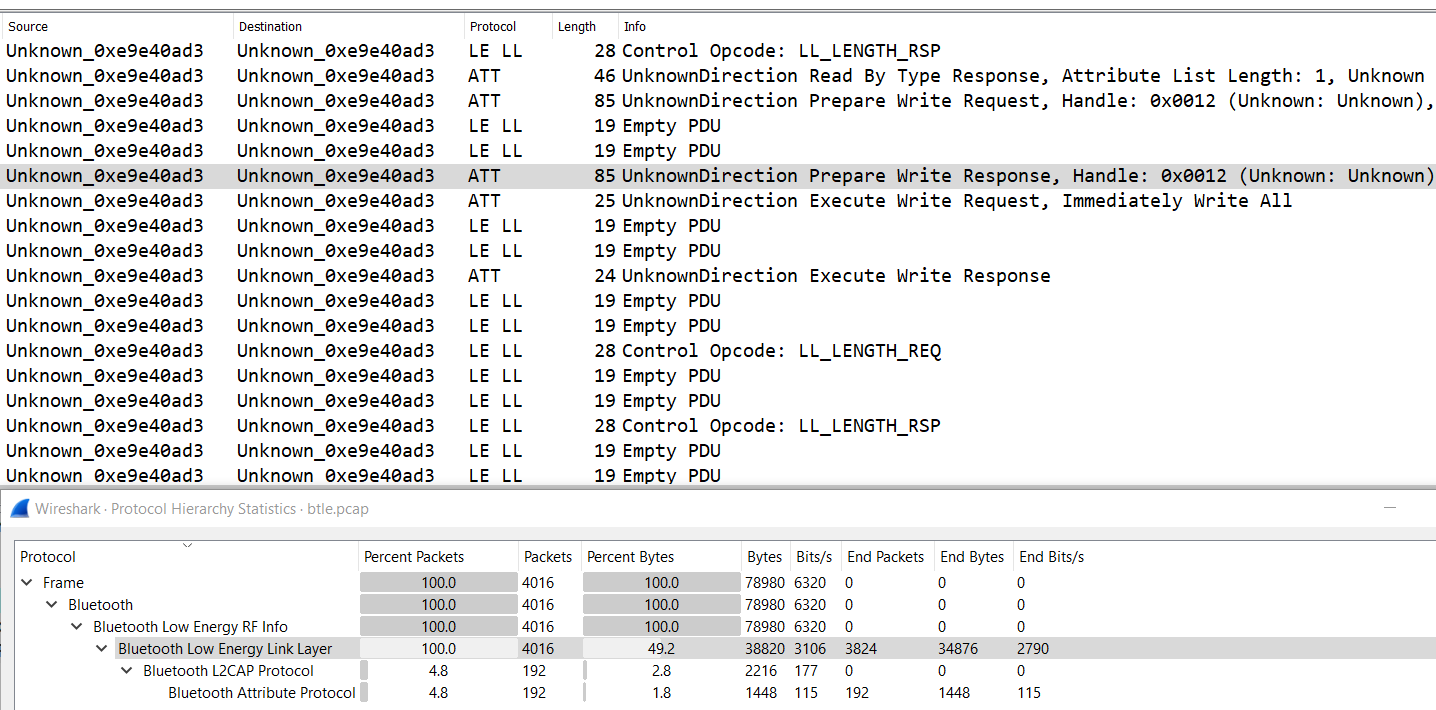
Packets of the Bluetooth Attribute Protocol (
ATT) appear more interesting because they seem to contain Read/Write requests, which should refer to the storing and retrieving of the flag from the remote database stated in the challenge’s description.
If we filter by btatt and scroll to the bottom, we can spot a Read Response packet containing the redacted flag in the Value attribute.
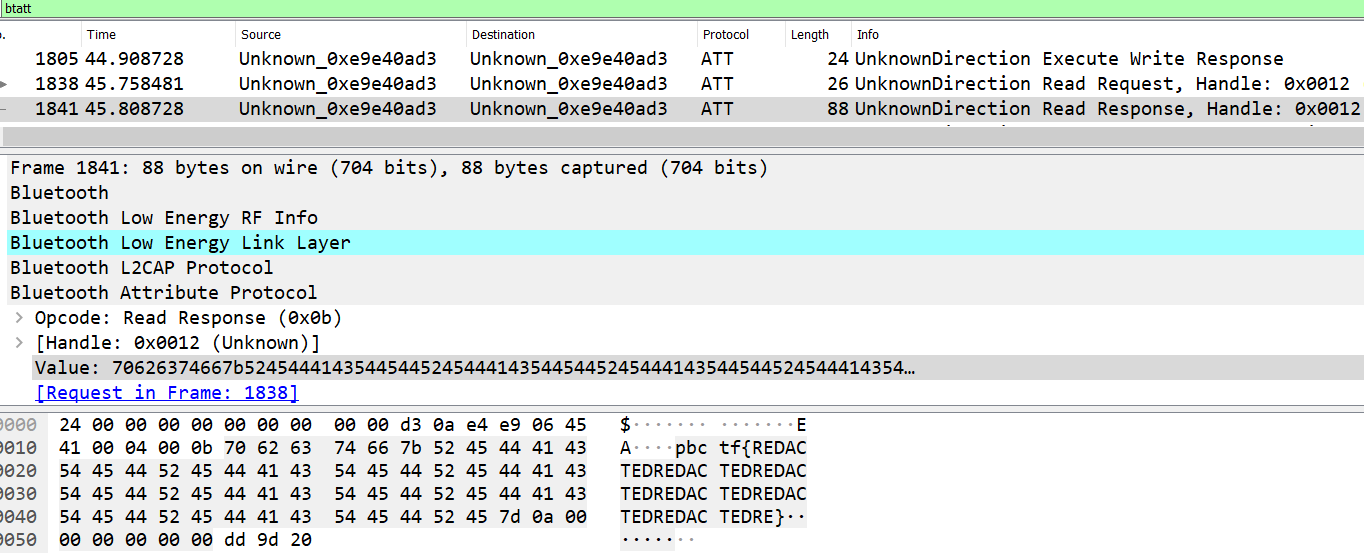
Before this single Read Request/Response, there’s a whole bunch of Prepare Write Request/Responses with long strings in the Value attribute being written at various Offsets. These are also known as Queued Writes which will all be written together by a separate Execute Write Request opcode.
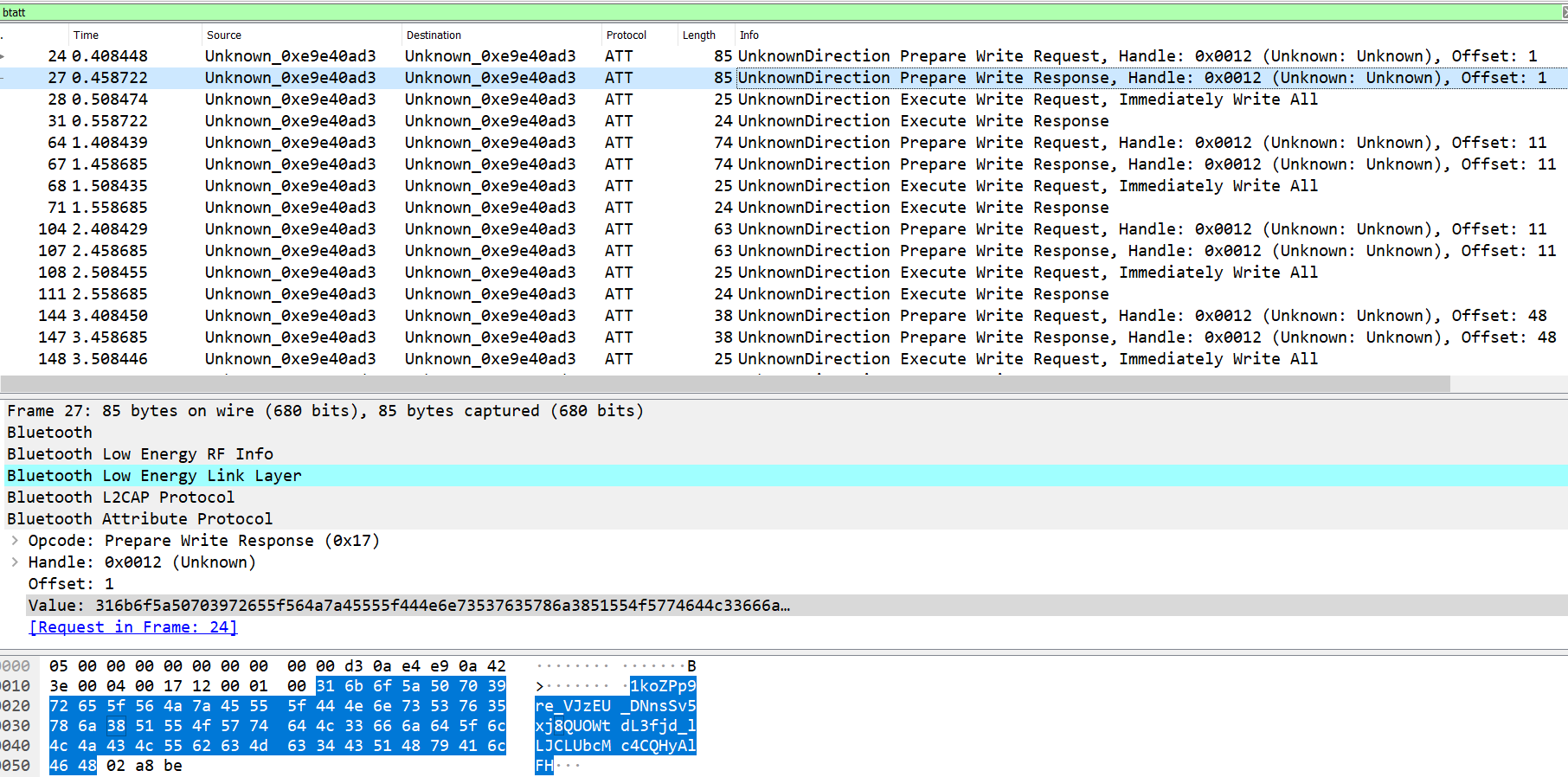
I posited that these long strings written at different overlapping Offsets would eventually overwrite each other and leave behind the flag in plaintext, so I replicated this behavior in Python using a io.BytesIO object which basically behaves like a file but only resides in memory.
In the script, I filtered for Prepare Write Responses with
btatt.opcode == 0x16, retrieved the Value attribute and wrote them at their corresponding Offsets to the BytesIO object.
|
|
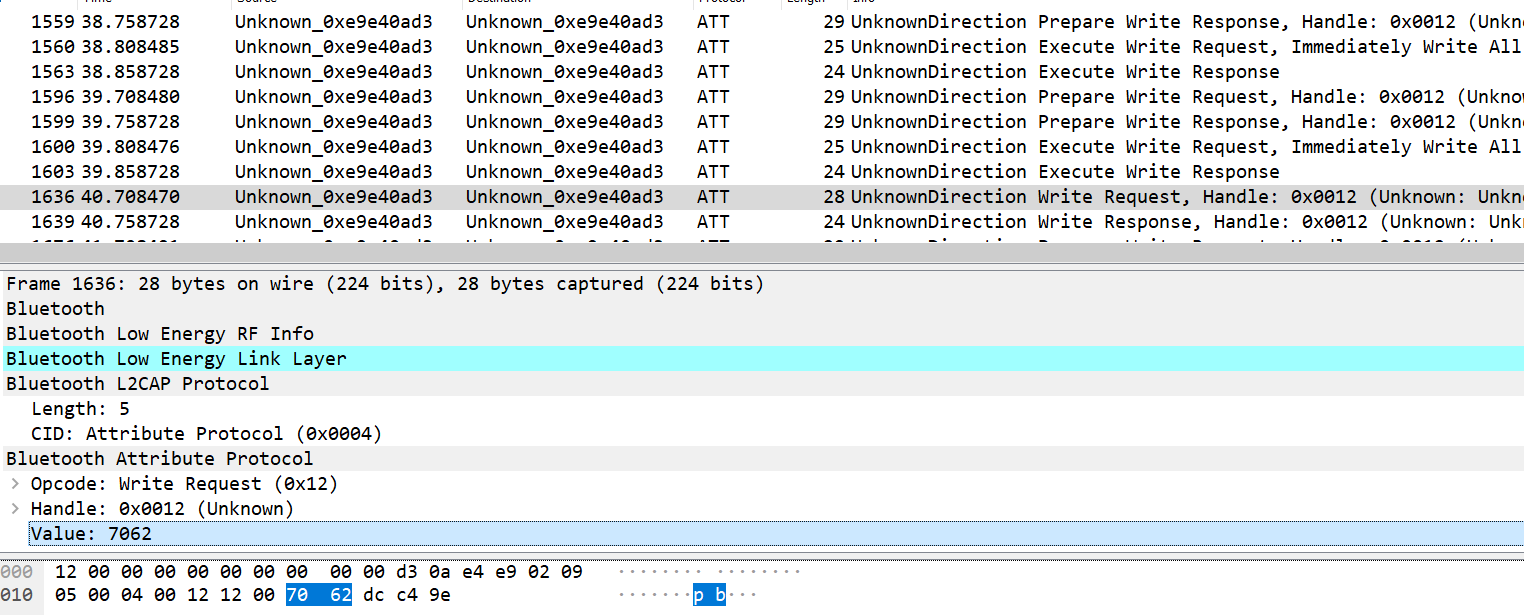
I also added an additional write of b"pb" to the beginning of the BytesIO object (lines 16-17) because among the sea of Prepare Write Requests, there was a sneaky standard Write for just these 2 letters. But of course, even if you missed this out, it wouldn’t matter because the flag format is known and you would know the correct first 2 letters.
|
|
Flag: pbctf{b1Ue_te3Th_is_ba4d_4_y0u_jUs7_4sk_HAr0lD_b1U3tO07h}
Reverse
Cosmo
To make it fair for everyone, this binary is fully portable. Run it anywhere! This definitely makes it easier, right?
Author: UnblvR
Attached: hello.com
Googling “cosmo portable binary” led me to discover that the binary is built with Cosmopolitan and is in what is known as the αcτµαlly pδrταblε εxεcµταblε (Actually Portable Executable) format. In short, the binary can run natively on multiple different operating systems without requiring a virtual machine or interpreter.
What are the implications of this? Static analysis will be more difficult, because there will be many distracting unused code paths present in the binary that are only meant to be taken when run on other operating systems. Thus, we will be doing mostly dynamic analysis.
First, basic black-box testing tells us that hello.com accepts a command-line argument that will be checked for the flag.
|
|
Next, I opened up the binary in IDA Pro and did a binary string search (Alt-B) for the UTF-8 string “Give flag”.
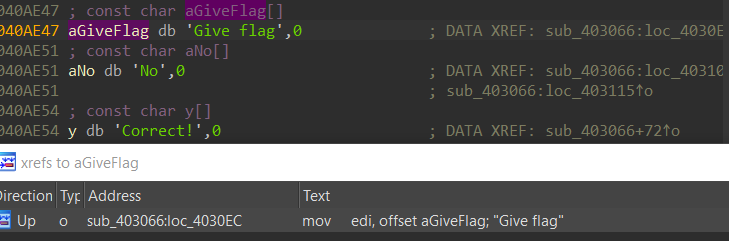
The strings “Give flag”, “No”, and “Correct” located next to each other all seem related to flag-checking and are all cross-referenced by
sub_403066. Thus, we’ll call this the check_flag function.
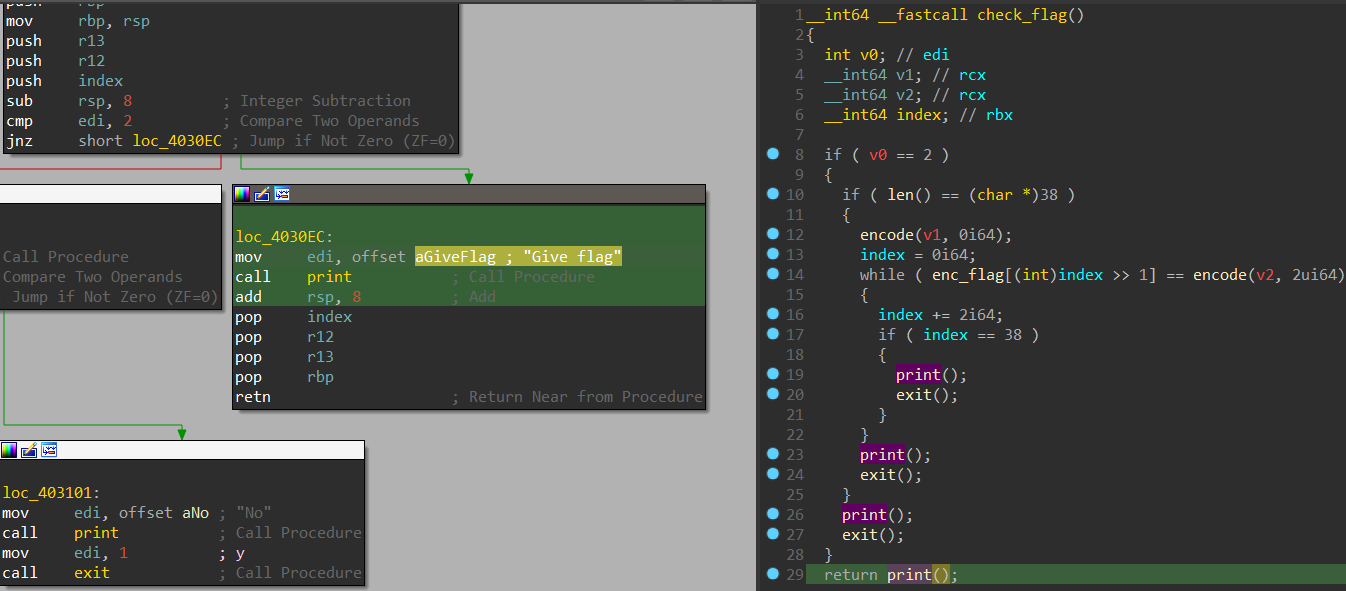
Through dynamic analysis with a dummy command-line argment passed in, I got a good sense of the significance of the variables and subroutines in this
check_flag function so I renamed them. Here’s what I understood from my analysis:
rdi(v0) is the number of command-line arguments including the executing binary’s filename (argc)rsiis the vector of command-line arguments (argv), so[rsi+8]is the 2nd command-line argument which is our input- length of input is checked to be 38 characters
enc_flagis an array of 19 QWORDs- 2 characters from the input are taken at a time, encoded, and checked against a QWORD from
enc_flag
You might notice there are variables in red (v0, v1, v2) in the pseudocode view on the right, and also subroutine calls like len(), print(), and exit() contain no arguments though the arguments can be clearly seen in the disassembly view on the left.
We can fix this by specifying proper custom function type declarations so that IDA knows where function arguments and return values are stored. IDA has helpful documentation for this.
As an example, right click on print(), click Set Item Type, and enter in the definition __int64 __userpurge print@<rax>(char *y@<rdi>). This essentially means that the argument y is passed in rdi, and the __int64 return value will be in rax. _userpurge means that the callee will clean up the stack. I’ll leave the rest of the function prototype redefinitions as an exercise for the reader, but once you’re done the pseudocode will make more sense:
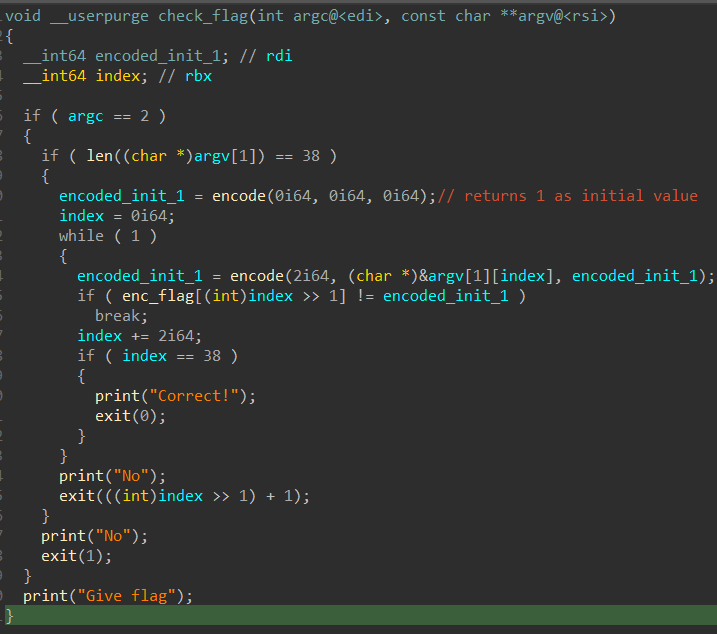
In the
encode subroutine,
- 1st argument will always be 2 which is the number of characters to take from our string input
- 2nd argument is our input
- 3rd argument is 1 for the first time
encodeis called but will be the encoded output for future runs
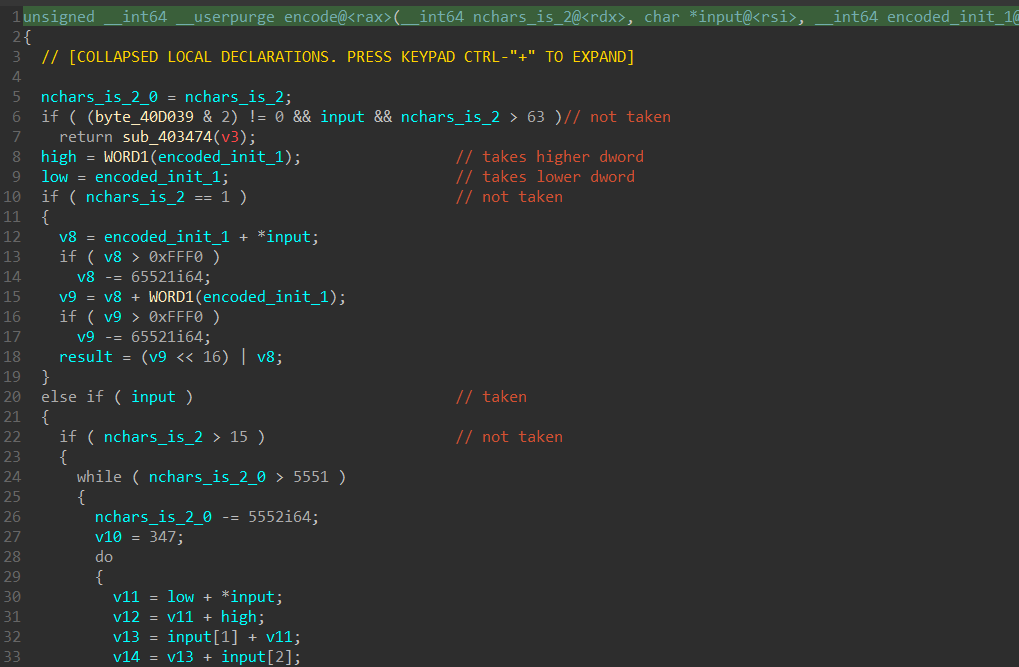
On lines 8 and 9, the 3rd argument is split into it’s high DWORD and low DWORD. So for the example of the 3rd argument being 1, the high DWORD will be 0 while the low DWORD will be 1.
Since the first argument is always 2, most of the if/while conditions are not taken and we can ignore a lot of the code. The main loop that is actually executed is below:
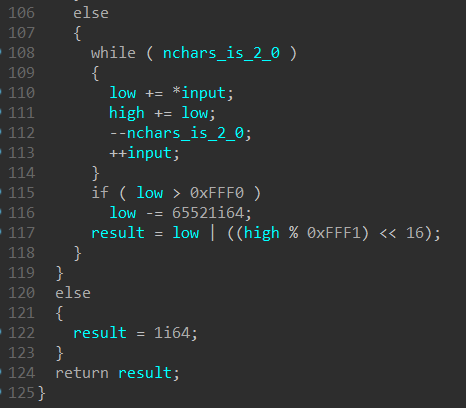
The result of this is the following where and refers to the 2 characters from the input:
and will then form the encoded QWORD result that is checked with enc_flag, and passed in as the 3rd argument to encode the next time is called to become the next and .
Armed with this knowledge, we can extract out the 19 QWORDs stored at enc_flag and basically do the reverse of the operations to get the flag:
|
|
|
|
Flag: pbctf{acKshuaLLy_p0rtable_3x3cutAbLe?}
Thanks for reading!