This was a Forensics CTF challenge from Cyberthon 2019’s Online Training. I do not have the original challenge title and description with me, although I do remember it was worth the highest possible points for a challenge and First Blood was mine :) I had forgotten what the solution was, but recently I decided to revisit this and figure it out once again after stumbling upon the mess of files I left behind on my hard drive from my original attempts to solve it back then.
In hindsight, while the solution is not difficult and could be pretty short, I found this challenge to be a good opportunity to showcase the different tools that one can usually look to when involved in PDF forensics. Thus, I’ll be taking a more long-winded and exploratory path below. Feel free to skip to the Summary!
| Tools Mentioned | Links |
|---|---|
| 010 Editor | https://www.sweetscape.com/010editor/ |
| Didier Stevens’ PDF Tools Masterpost | https://blog.didierstevens.com/programs/pdf-tools/ |
| pdf-parser | http://didierstevens.com/files/software/pdf-parser_V0_7_4.zip |
| pdfid | http://didierstevens.com/files/software/pdfid_v0_2_7.zip |
| polyfile | https://pypi.org/project/polyfile/ |
| mutool | https://www.mupdf.com/downloads/index.html |
| qpdf | https://github.com/qpdf/qpdf |
| iLovePDF Repair PDF Online | https://www.ilovepdf.com/repair-pdf |
Details
We are given VoIP-Research.pdf which throws an error message if opened in standard PDF viewers.
So how do we check out the contents of this PDF? We can use 010 Editor, which is essentially a hex editor on steroids because it comes with binary templates that parses various file format structures and displays them for easy analysis. Conveniently, 010 Editor already comes with a
PDF.bt binary template from its default repository which can parse our malformed PDF file for us.
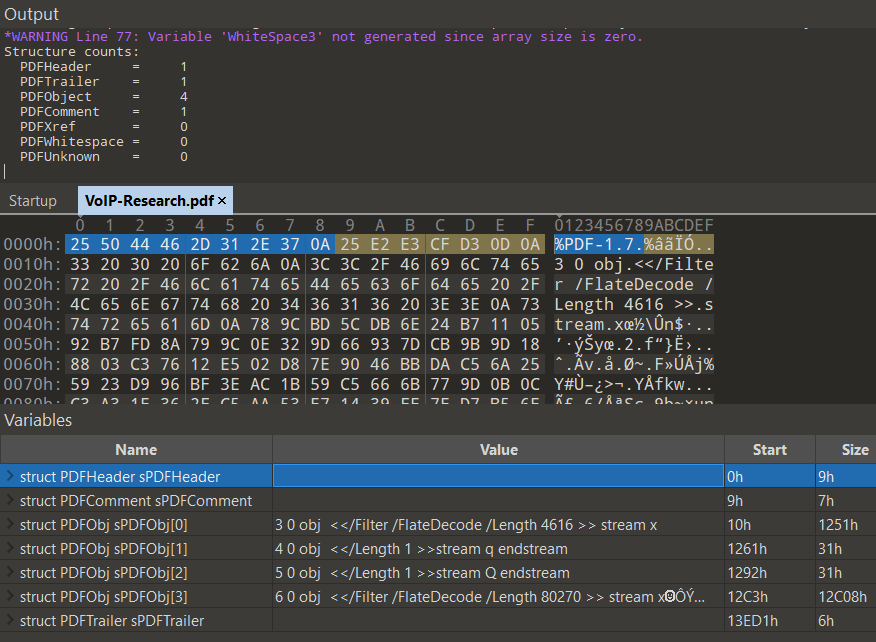
Running the template shows us that 4 PDF objects were found! Objects 4 and 5 (denoted as
4 0 obj and 5 0 obj) contain streams of length 1 so we can ignore those. Objects 3 and 6 (3 0 obj and 6 0 obj), on the other hand, are much larger-sized compressed FlateDecode streams and hence are of greater interest.Now if we were to run Didier Steven’s pdf-parser, we should be able to list the same objects, decode the streams we need and see what’s in there.
Command:
|
|
Output:
|
|
Wait what? Why do we only get 3 objects - Objects 3, 4, and 5? Where did our previously-seen object 6 go?
For the sake of introducing more tools, let’s also test this out with polyfile. It can be installed with the standard pip3 install polyfile and then ran with a flag to generate an interactive HTML file for us to explore the structure of the PDF.
|
|

Interestingly,
polyfile also only manages to display 3 of the objects.To figure out what’s going on, let’s look back deeper into the PDF objects in 010 Editor. Comparing the
FlateDecode Object 3 which displays correctly and the missing FlateDecode Object 6, we notice that Object 6 lacks an EndObject and WhiteSpace3 after its Data section. It just goes straight to the PDFTrailer denoted by %%EOF.
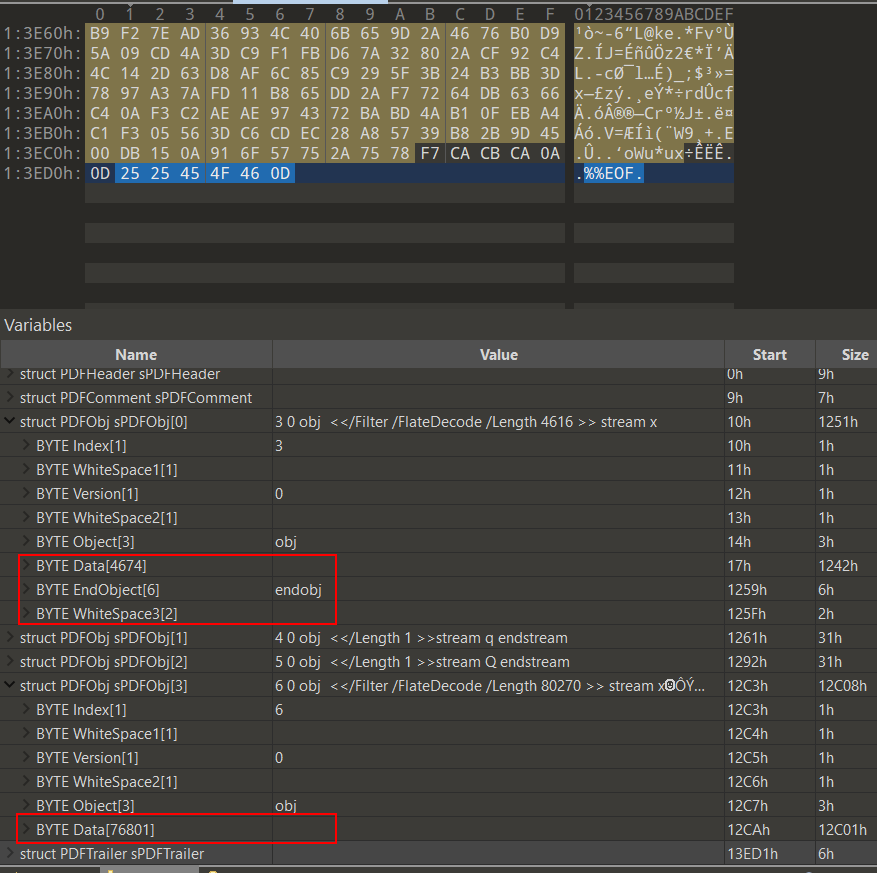
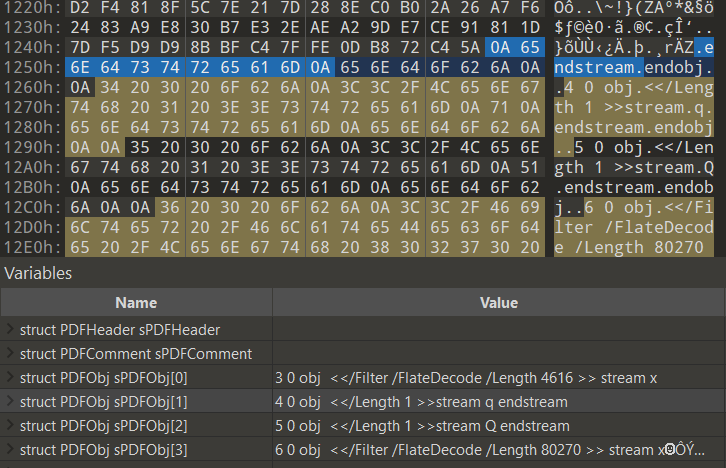
In fact, Object 6 is also lacking the
endstream keyword at the end of its Data stream section. We can see that Objects 3, 4, and 5 have this keyword before endobj. As specified on page 36, section 3.2.7 ‘Stream Objects’ of the PDF Reference, Third Edition, this endstream keyword is necessary along with the starting stream keyword as a matching pair. This is also the reason why Object 6 was not picked up by pdf-parser or polyfile.
If we run Didier Stevens’ pdfid on the PDF with
pdfid.py VoIP-Research.pdf, we can actually see that there are a mismatched number of obj/endobjs and stream/endstreams.
|
|
While we could remedy this by manually adding in the missing keywords, let’s introduce another tool to help fix this automatically: mutool. In this case, we will use mutool clean which happens to repair the broken object. Do bear in mind that this may not necessarily always work. From mutool clean’s output we see that it has correctly identified that a PDF object is missing the endobj token. It also tried to fix other problems like a missing xref table, though this will not be relevant to the solution.
Just for the record, both qpdf and https://www.ilovepdf.com/repair-pdf did not work to repair the PDF file automatically. But you can always keep them in mind when trying to repair other files.
Command:
|
|
Output:
|
|
pdfid now shows that we have a matching number of obj/endobjs and stream/endstreams
|
|
and pdf-parser is now able to detect Object 6!
|
|
With this, we can inflate Object 6 and inspect its contents.
Command:
|
|
Output (truncated):
|
|
Object 6 appears to be some kind of graphics object because of its various graphics operators like q, Q, sc, m, and l. This is detailed on page 134, in table 4.1 ‘Operator Categories’ of the same PDF Reference, Third Edition we used earlier.
To recover this graphics object, we can use mutool create to create a completely new PDF file based on graphics commands of our choice.
First, replace all occurrences of the string \n with actual newline characters in the decoded object stream output from pdf-parser:
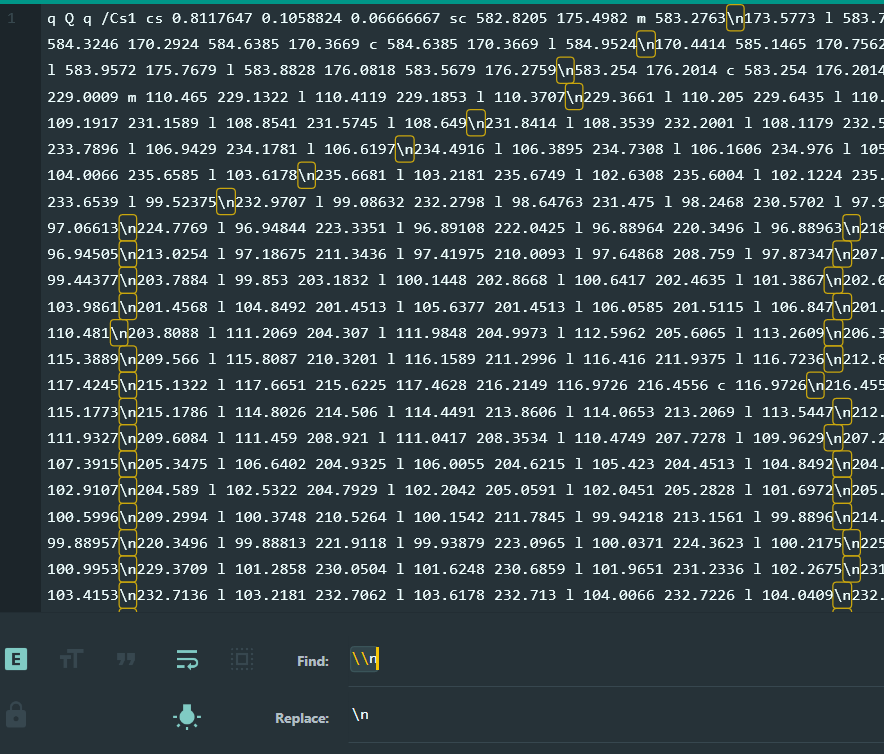
Second, saving the replaced object stream contents into a text file like
graphics.txt, we can then use
|
|
to create a new PDF with the default name of out.pdf based on the graphic operators and operands in graphics.txt.
We can now open the PDF and view the graphical flag with no problems 😄

Flag:
CTFSG{D0GG0_8T3_MY_P4P3R}
Summary
- Inspect PDF in 010 Editor with binary template and spot the malformed PDFObj. This research can be augmented with output from
pdf-parserandpdfid. - Fix the malformed PDFObj manually or with
mutool clean. - Inspect stream contents of PDFObj, decoding with filters if needed, to determine the type of object.
- Fix formatting of stream contents with a simple find and replace
- Use
mutool createto generate a new clean PDF file with the object contents so that we can view it
A possible shortcut solution that I have not tested out yet is to just copy out the compressed object stream from 010 Editor and inflate it elsewhere with some Python module. Perhaps you could try this out with any other similar PDF and let me know! I’m not sure if I’m allowed to share this particular challenge PDF file because there may be some sort of challenge creators’ copyright issues.
Thanks for reading! I hope at least one of these tools covered will be useful to you in the future.